用Python解析Epub格式文件

一、开发环境
1.1、系统环境
- windows 10 + python 3.9
- Vscode V1.65.2
- vs插件:xmltool、Python
1.2、注意事项
-
配置好自己的vscode的代码片段
-
安装好vscode的关键插件(xmltool、Python)
- 设置好xmltool的Xpath的 快捷方式
- 配置好vscode的python开发环境
- 配置好python 的虚拟环境(我使用的pipenv)
1.3、Python的包环境
-
系统包
-
第三方包,需要在虚拟环境中安装好
包名 作用 安装 yaml 应用或工具的配置文件信息读取 pipenv json json的处理包 zipfile zip压缩文件的处理包 pathlib python 3.x 的目录路径处理包,替代os.path lxml 解析xml文件,不过只能读取xml文件 logging 用于记录运行日志,同时也可以用于调试过程中的错误或数据检查 PIL 需要处理电子书的封面图像,可能需要缩略图 Jinja2 用于根据模板生成文件的方法 (生成MD格式文件) 其他包如果有变化,后期在更新说明。
1.4、应用程序目录结构
比较简单,这里就不贴了.......
二、主要知识点
2.1、学习使用yaml进行配置信息读取
yaml的配置......
读取yaml文件前需要安装pyyaml和导入yaml模块
pipenv install pyyaml
最新版本是6.0 ;PyYAML==6.0
示例:
(关于yaml的目录结构,在开发时需要注意,这里我就不细节展开说明目录的处理了,请自行思考)
《yaml文件内容》===============: ``` import json from jinja2 import Template
temps = Template('haha namepad= {{ namepad }} !!!!--- strfn= {{ strfn }}') dic_var = { "namepad" : "who123" , "strfn" : "ssshahah123" } s = temps.render(dic_var)
print(s) ```
《python读取yaml》=============:
import yaml
import os
def getYamlData(ymal_fpath):
'''
打开yaml文件,读取并返回一个数据字典。
'''
fl = open(ymal_fpath,'r', encoding="utf-8")
fl_data = fl.read()
fl.close()
yl_data = yaml.load(fl_data,Loader=yaml.FullLoader) #返回字典类型
return yl_data
#getYamlData
def getYamlByKey(yaml_fpath,strkey):
'''
1-打开yaml文件,读取并返回一个数据字典。
2-读取yaml文件中某个配置的值,并返回字符串。
异常:
如果Key输入的错误,或没有找到这个Key,则返回字符串 Key_Error
'''
yldict = getYamlData(yaml_fpath)
try:
return yldict[strkey]
except KeyError:
return "Key_Error"
raise KeyError
#try
#getYamlByKey
curpath = os.path.abspath("../conf") # 获取配置文件所在的目录
yl_path = os.path.join(curpath,"config.yaml")
if(os.path.isfile(yl_path)):
yldict = getYamlData(yl_path)
print(yldict)
print(yldict['psw'])
print(yldict['use1'])
print(yldict['use1']['a'])
print(getYamlByKey(yl_path,'psw'))
else:
print("配置文件未找到,请确认配置文件是否真的存在。")
python:yaml模块 - 简书 (jianshu.com)
python配置yaml - 测试-安静 - 博客园 (cnblogs.com)
2.2、学习zip文件处理
zip文件处理.....
Python中的zipfile模块使用实例 - 简书 (jianshu.com)
2.3、学习json的数据处理
Python JSON | 菜鸟教程 (runoob.com)
Python3 JSON 数据解析 | 菜鸟教程 (runoob.com)
2.4、学习path目录或文件的处理方式
python路径操作新标准:pathlib 模块 - 和牛 - 博客园 (cnblogs.com)
Python文件操作,看这篇就足够 - 知乎 (zhihu.com)
2.5、学习xml文件处理(主要是lxml读取)
学习URL地址:
问题1💀:解析xml格式的文件时要注意名称空间的问题:
示例代码:
parser = etree.XMLParser(encoding = "utf-8")
ht_str = etree.parse(opffile, parser=parser)
print(ht_str)
xpathquery_str = "//package/metadata/dc:publisher"
q_result = ht_str.xpath(xpathquery_str)
我的XML文件内容:
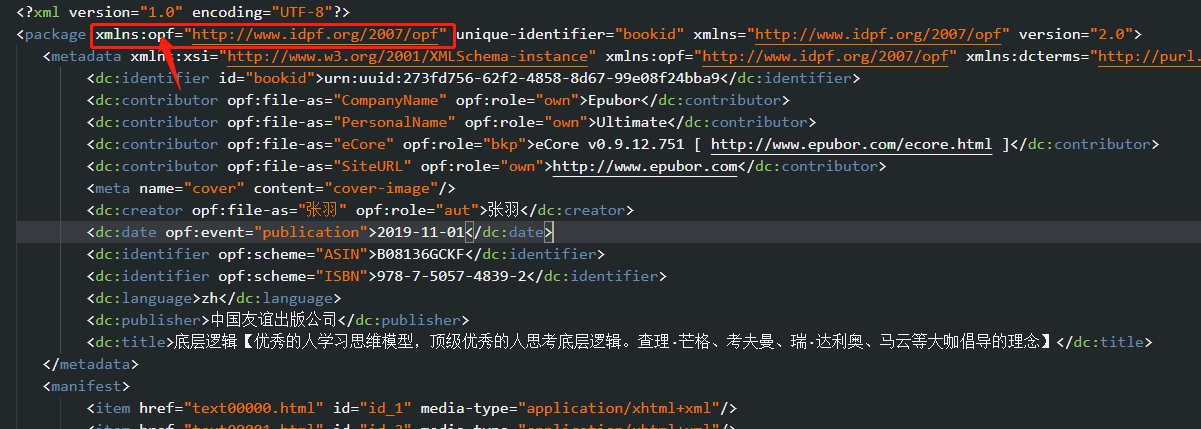
报错:lxml.etree.XPathEvalError: Undefined namespace prefix
修改上面的python代码最后一行:在运行就不报这个错误了。
q_result = ht_str.xpath(xpathquery_str, namespace={'opf': 'http://www.idpf.org/2007/opf'})
问题2💀:namesapce字符拼写问题:
🔥🔥🔥
特别注意:namespace 和 namespaces 绝对不能错哦 ;上面的代码是不会报错;但是会报一个另外的错误啊,这个另外错误花费了两个小时啊......
lxml.etree.XPathResultError: Unknown return type: dict
🔥🔥🔥
xpathquery_str = "//dc:title/text()"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
问题3💀:opf文件的xpath查询问题:
这个问题难点是,中文的很多文章中并没有对解析xpath查询讲得更深入吧,(咱英语也不是很好啊,慢慢看能看懂的水平.....😕), 我已经花了两个多小时了啊,代码是这样的:
# XMLNS
# Namespaces (Epub文件中Opf文件中定义的名称空间,用一个字典变量定义)
NS = { 'opf': 'http://www.idpf.org/2007/opf',
'xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'dcterms': 'http://purl.org/dc/terms/',
'ns0': 'http://www.idpf.org/2007/opf',
'dc': 'http://purl.org/dc/elements/1.1/',
}
# etree.XMLParser(encoding = "utf-8")
parser = etree.XMLParser(encoding = "utf-8")
ht_str = etree.parse(opffile, parser=parser)
print(ht_str)
xpathquery_str = "//dc:title/text()"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
print("图书标题=" + q_result[0])
# result=html.xpath('//li[@class="item-1"]/a/text()') #获取a节点下的内容
xpathquery_str = "//dc:identifier[@opf:scheme='ISBN']/text()"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
print("ISBN=" + q_result[0])
#log.logger.info(q_result)
xpathquery_str = "//dc:identifier[@opf:scheme='ASIN']/text()"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
print("ASIN=" + q_result[0])
xpathquery_str = "//dc:date/text()"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
print("创建时间=" + q_result[0])
xpathquery_str = "//dc:creator/text()"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
print("创建人=" + q_result[0])
xpathquery_str = "//reference/@href"
q_result = ht_str.xpath(xpathquery_str)
print(q_result)
xpathquery_str = "//item[@properties='cover-image']/@href"
q_result = ht_str.xpath(xpathquery_str)
print(q_result)
xpathquery_str = "//item[@properties='media-type']"
q_result = ht_str.xpath(xpathquery_str, namespaces=NS)
print(q_result)
关键是上面的代码中,前部分(dc:xxx)的哪些元素能获取到信息,但是后面哪些查询就不灵了啊。
content.opf就不帖了;
试错过程:
1、我不停的试xpath的查询语句,怎么都不行,我怀疑还是跟名称空间有关系。
2、所以用一个string的方式(去掉名称空间的str)来测试,代码参考网上的(w3cschool)。
🔥🔥🔥 真是太难了啊:
对于content.opf 格式的XML文件解析,带很多的namespace的;这样的文件使用两种方式进行xpath进行查询
🔥对于不带ns的标记,使用HTML的格式化后在xpath查询;
html=etree.HTML(text.encode("utf-8")) #初始化生成一个XPath解析对象
result=etree.tostring(html,encoding='utf-8') #解析对象输出代码
xpq_str = "//item[@id='id_6']/@href"
print(html.xpath(xpq_str))
🔥对于带ns的标记,使用XML的格式化后的xpath查询:
dom = etree.XML(text.encode("utf-8"))
#xpq_str = "//dc:identifier[@opf:scheme='ISBN']/text()"
xpq_str = "//dc:title/text()"
aid = dom.xpath(xpq_str, namespaces=NS)
print(aid)
Python3 XML 解析 | 菜鸟教程 (runoob.com)
python3解析库lxml - Py.qi - 博客园 (cnblogs.com)
使用lxml解析xml文件 - 阿布_alone - 博客园 (cnblogs.com)
lxml解析包(二):对于xpath中含有命名空间的xml文件解析_不愿透露姓名の网友的博客-CSDN博客
2.6、学习logging日志包的使用方法
logging可以在哪些场景下使用,比如:替代print;记录日志到文件、输出结果到控制台......
logging的包使用其实不难,但是想做一个AOP的开发试验,就需要了解Python的装饰器知识了,日志这个方模需要学习内容还是很多的。
2022-3-21;测试学习logging
-
编写一个可以输出到控制台、输出到日志文件中的类
-
在其他需要调用该类的方法引用该类,并将调用输出日志信息,调用方法大概如下:( 这个程度目前应该够用了吧...... )
``` from logtest import Loggers
......... if(os.path.isfile(yl_path)): yldict = getYamlData(yl_path)
log = Loggers(level='info') log.logger.info("我的logging测试==" + yldict) log.logger.info(getYamlByKey(yl_path,'psw'))else: print("配置文件未找到,请确认配置文件是否真的存在。") ```
参考:
python 中面向切面编程AOP和装饰器 - 简书 (jianshu.com)
python中logging日志模块详解 - 咸鱼也是有梦想的 - 博客园 (cnblogs.com)
python logging详解及自动添加上下文信息 - xybaby - 博客园 (cnblogs.com)
一看就懂,Python 日志 logging 模块详解及应用 | 静觅 (cuiqingcai.com)
Python之日志处理(logging模块) - 云游道士 - 博客园 (cnblogs.com)
2.7、最重要的是学习了Epub格式规范和解析
Epub2基础知识介绍 - 大西瓜3721 - 博客园 (cnblogs.com)
EPUB3.0内容文件规范中文版_免费.pdf (book118.com)
2.8、学习Jinja2 模板生成MD格式文件
使用Jinja2 可试用模板的方式,构造MD文件
请注意先安装Jinja2;
pipenv install Jinja2
示例1:
import json
from jinja2 import Template
temps = Template('haha namepad= {{ namepad }} !!!!--- strfn= {{ strfn }}')
dic_var = { "namepad" : "who123" , "strfn" : "ssshahah123" }
s = temps.render(dic_var)
print(s)
示例2:
2.9、学习图片文件处理
图片图像文件处理.....
Python基础模块:图像处理模块@PIL(批量分类处理图片及添加水印)_可以叫我才哥的博客-CSDN博客
python:PIL库学习笔记 - Jessie- - 博客园 (cnblogs.com)
python PIL 图像处理 - 简书 (jianshu.com)
python+glob+PIL+plt 图片批量导入+显示_ClearLon的博客-CSDN博客_pil批量读取图片
三、应用需求
-
输入:
- 一个epub电子书文档
- 一个MD文章的模板文件
-
处理:
- 获取epub电子书的书名
- 获取电子书的封面
- 获取电子书的内容简介
- 生成一个该电子书的介绍的MarkDown的文章
-
输出:
- 输出电子书的封面文件(.jpg / .png),保存在特定目录
- 输出md文件,保存在特定目录
四、设计思考
首先epub文件处理(读取或写入)应该是单独的功能,可以按包的思路去实现,未来这个可以复用。
使用epub的这个文件处理工具,可以进行epub文件的信息获取,用获取的信息可以做其他的应用了,比方:这里的需求是生成MD格式文件

五、学习验证测试
5.1 测试操作epub
构建一个类 epub
-
导入主要的包
-
创建一个类的构建函数
-
定义类的公有属性
- zip文件(电子书epub文件)实例;
- opf文件实例,一个lxml对象;
- toc文件实例,一个lxml对象;
- opf中的元数据信息实例,用字典类型保存;
- 电子书epub文件的封面图片对象实例;
-
创建公有方法,获取电子书名
-
创建公有方法,获取电子书一些基本信息,并复制到Metadata中
-
创建公有方法,获取opf文件实例
-
创建公有方法,获取toc文件实例
-
创建公有方法,获取电子书封面文件
-
创建公有方法,改名保存的方法
5.2 测试生成MD文件
今天先就这样吧,休息.............

兴奋起来吧.....; 好看吧!
六、开始实现
6.1、先编写epub文件处理工具
6.2、再编写生成MD文件函数
源码:pyepub
