langchain-chatchat源码分析
一、背景
准备为自己的网站站点做一个AI推荐图书的功能,拟采用AI的方式实施,特别学习了langchain-chatchat;
学习目的:
- 了解langchain-chatchat的运行原理;
- 了解如何进行改造;
二、langchain-chatchat环境及相关功能说明
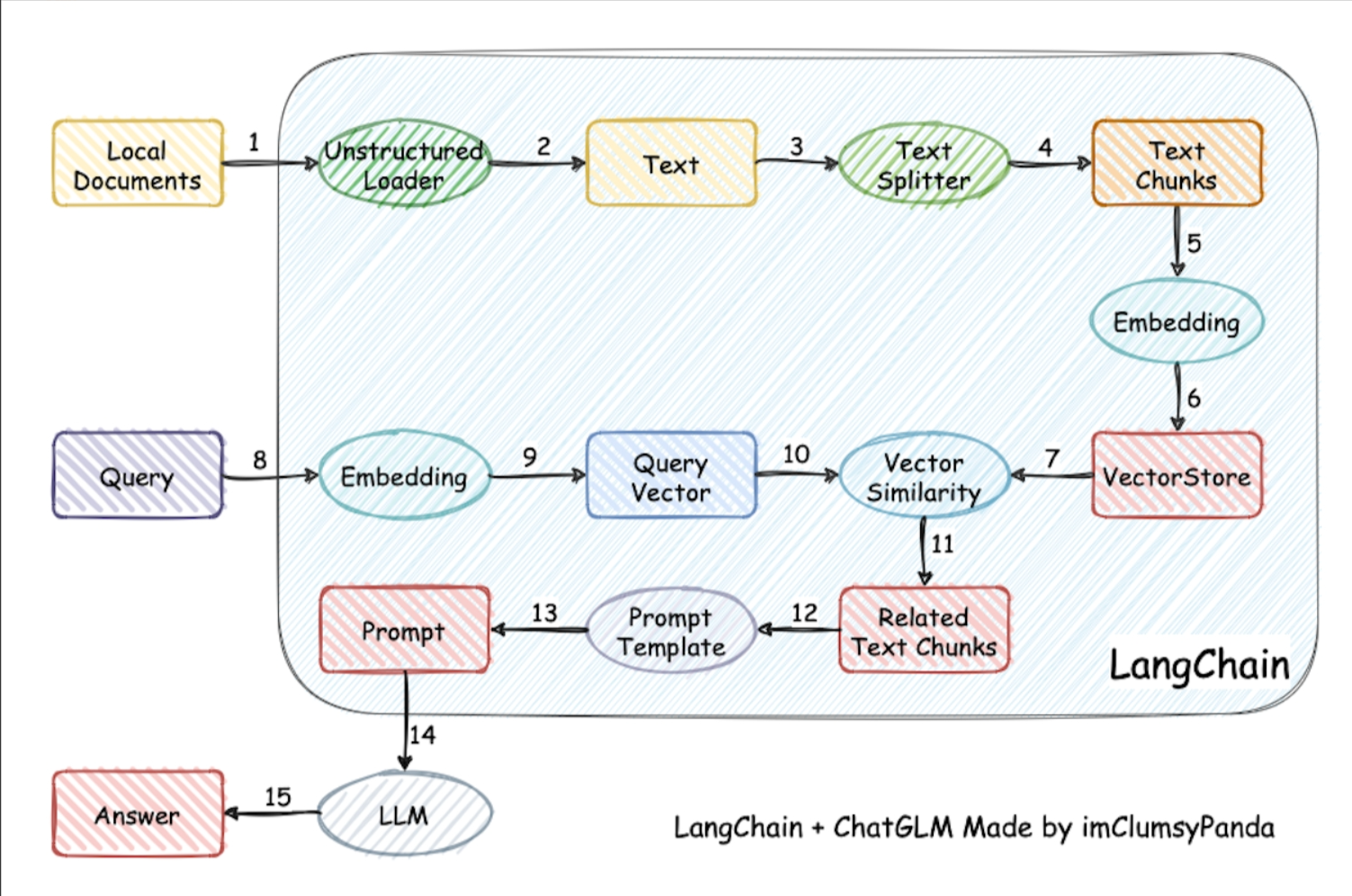
从文档处理角度来看,实现流程如下:
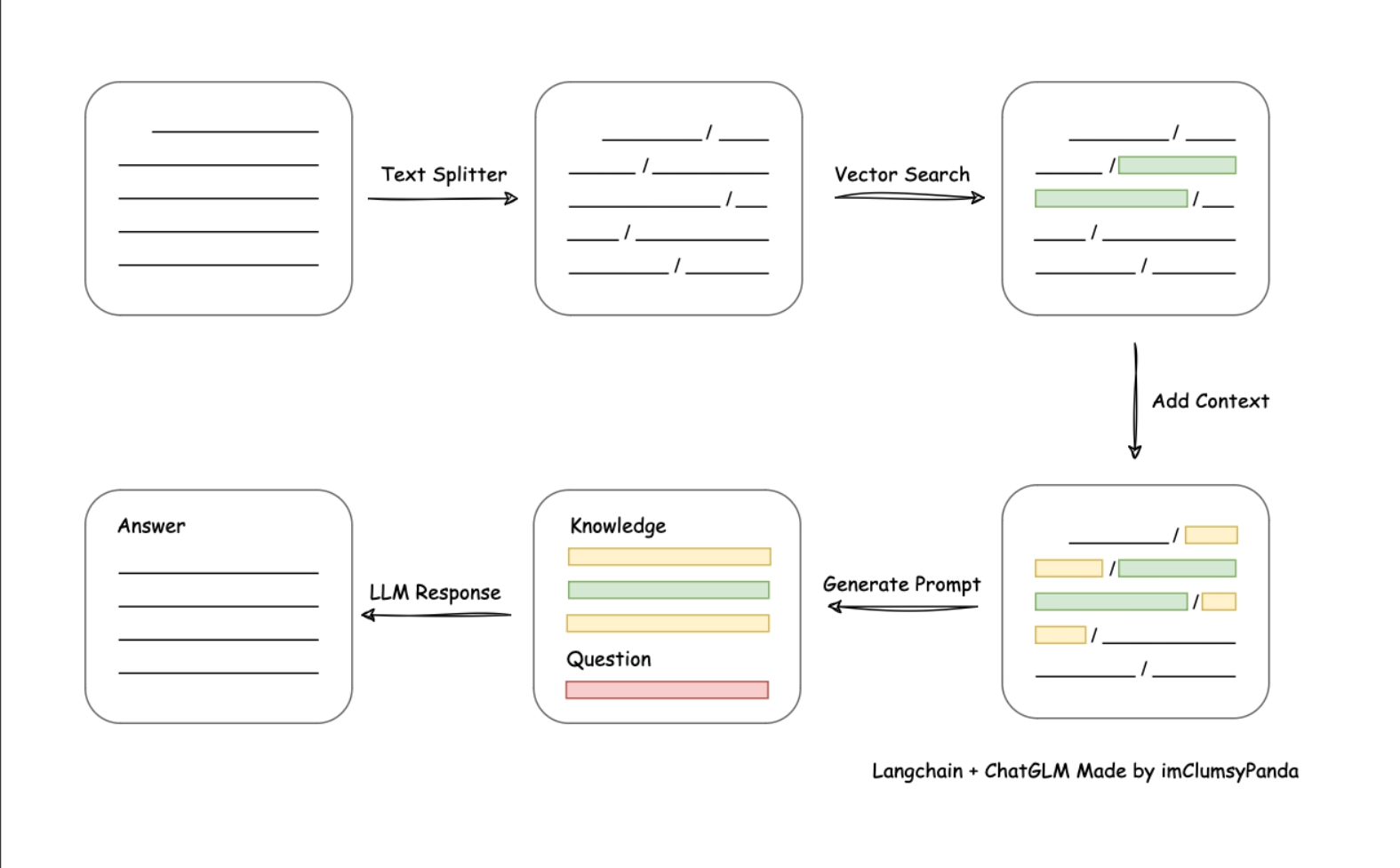
1- langchain-chatchat,2023-12-16 发布的最新版本号:0.2.28
2- github上的开源说明中提供的是docker安装,网上有人实验,这个方式部署并不成功,主要问题好像是docker容器与nivada显卡驱动的互通问题
3- 本质上langchain-chatchat其实是一个集成器,相当于利用langchain将LLM,应用数据库,本地知识库(文件),集成到一起使用
4- 本地化部署的LLM模型是chatGLM-6b,也可以使用在线的LLM(chatGPT 通义千问等等其他,很多)
5- 支持的embedding模型也分本地和在线的, 目前在线的好像主要是(hugface, chatGPT, 通义千问,文心一言)的这些
6- 支持矢量数据库, 默认:faiss; 还未看到如何连接milvus向量数据库
class SupportedVSType:
FAISS = 'faiss'
MILVUS = 'milvus'
DEFAULT = 'default'
ZILLIZ = 'zilliz'
PG = 'pg'
ES = 'es'
7- 目前使用的sqllite本地数据库保存相关应用所需数据
三、应用程序结构
核心应用包
langchain; fastchat; fastapi;
代码结构:
-
configs/ 配置文件路径
-
server/ api服务、大模型服务等服务程序等核心代码
-
webui_pages/ webui服务
-
startup.py 启动脚本
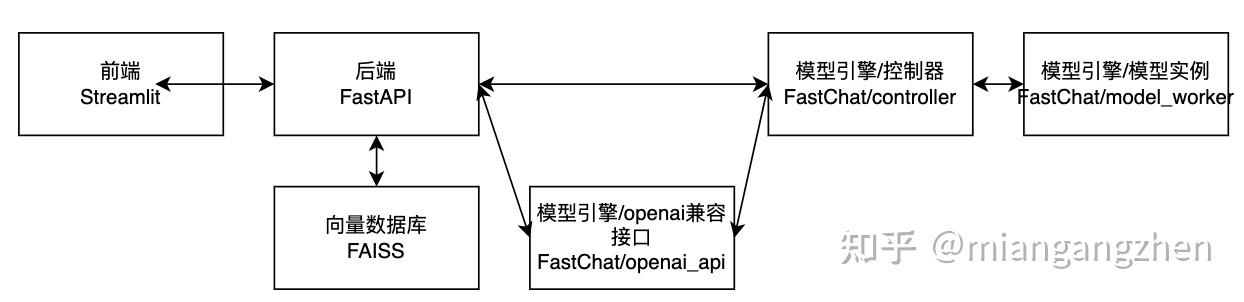
// TODO
四、本地sqllite数据结构
每个表包含这几个字段:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | Integer | 主键ID |
| create_time | DateTime | 创建时间 |
| update_time | DateTime | 更新时间 |
| create_by | String | 创建者 |
| update_by | String | 更新者 |
summary_chunk表,用于存储file_doc中每个doc_id的chunk 片段,
数据来源:
用户输入: 用户上传文件,可填写文件的描述,生成的file_doc中的doc_id,存入summary_chunk中
程序自动切分 对file_doc表meta_data字段信息中存储的页码信息,按每页的页码切分,自定义prompt生成总结文本,将对应页码关联的doc_id存入summary_chunk中
后续任务:
矢量库构建: 对数据库表summary_chunk中summary_context创建索引,构建矢量库,meta_data为矢量库的元数据(doc_ids)
语义关联: 通过用户输入的描述,自动切分的总结文本,计算
语义相似度
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | Integer | ID |
| kb_name | String(50) | 知识库名称 |
| summary_context | String(255) | 总结文本 |
| summary_id | String(255) | 总结矢量id |
| doc_ids | String(1024) | 向量库id关联列表 |
| meta_data | JSON | 默认为空的JSON对象 |
conversation表,聊天对话模型:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | String(32) | 对话框ID |
| name | String(50) | 对话框名称 |
| chat_type | String(50) | 聊天类型 |
| create_time | DateTime | 创建时间 |
knowledge_base表,知识库模型
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | Integer | 知识库ID |
| kb_name | String(50) | 知识库名称 |
| kb_info | String(200) | 知识库简介(用于Agent) |
| vs_type | String(50) | 向量库类型 |
| embed_model | String(50) | 嵌入模型名称 |
| file_count | Integer | 文件数量 |
| create_time | DateTime | 创建时间 |
knowledge_file表, 知识文件模型
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | Integer | 知识文件ID |
| file_name | String(255) | 文件名 |
| file_ext | String(10) | 文件扩展名 |
| kb_name | String(50) | 所属知识库名称 |
| document_loader_name | String(50) | 文档加载器名称 |
| text_splitter_name | String(50) | 文本分割器名称 |
| file_version | Integer | 文件版本 |
| file_mtime | Float | 文件修改时间 |
| file_size | Integer | 文件大小 |
| custom_docs | Boolean | 是否自定义docs |
| docs_count | Integer | 切分文档数量 |
| create_time | DateTime | 创建时间 |
file_doc表,文件-向量库文档模型
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | Integer | ID |
| kb_name | String(50) | 知识库名称 |
| file_name | String(255) | 文件名称 |
| doc_id | String(50) | 向量库文档ID |
| meta_data | JSON | 默认为空的JSON对象 |
message表,聊天记录模型
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | String(32) | 聊天记录ID |
| conversation_id | String(32) | 对话框ID |
| chat_type | String(50) | 聊天类型 |
| query | String(4096) | 用户问题 |
| response | String(4096) | 模型回答 |
| meta_data | JSON | 默认为空的JSON对象 |
| feedback_score | Integer | 用户评分 |
| feedback_reason | String(255) | 用户评分理由 |
| create_time | DateTime | 创建时间 |
五 autodl运行环境
运行虚拟环境
conda activate chatchat
下载模型:
# cd <chatchat目录>
# 下载chatglm3, 会在<chatchat目录>/chatglm3-6b
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
# 下载m3e-base模型,
git clone https://www.modelscope.cn/Jerry0/m3e-base.git
配置文件
# 在config目录下, 将所有的example 修改为py文件
cp kb_config.py.example kb_config.py
# 启动
python startup.py --all-webui
python startup.py -a
六 附录
使用 Langchain-Chatchat 进行本地部署的完整指南 - 掘金 (juejin.cn)
Langchain-Chatchat项目:ChatGLM3的工具增强真的太香了! - 知乎 (zhihu.com)
作者: CLP ; 日期: 2023-12-26 ; 地点: 武汉; 天气: 晴
QQ: 53258372; Mail : 53258372@QQ.com
微信:
