
还在为水印烦恼,Python帮你搞定
一. 个人需求
我网盘里面有很多图片,大部分是从今日头条、小红书下载下来并加了水印的,水印大多出现在左下角或右下角。在发表头条文章时,需要引用这些图片,但是由于水印的存在,都会让人觉得不太舒服,所以我每次都会花时间用ps处理一下。由于我有一点Python 的开发知识,我就想着是否可以利用Python编写一个脚本去批量去除这些水印呢?因此我开始研究python批量去除水印的方法。
这个是个人的需求, 暂未考量做成功能
二. 初步期望
- 我将需要使用的图片复制到一个统一的目录下(图片估计有1万多张), 目录名称: watermark_src
- 在cmd终端窗口中运行一个命令(
python rm_wm.py), 将上面这个目录下的所有图片自动检测并去除水印 - 自动将这些去除水印的图片保存到一个目录下面: watermark_remove
三. 方法预研究
我从网上收集学习去水印的方法, 总结下来有下面几种:
1- 直接用数学计算的方法去除
2- 用深度学习的算法去除
3- 借助OpenCV工具+数学方法去除
我目前没有GPU啊, 还是只有用CPU了, 所以我觉得用OpenCV的方式可能要成本更低
我还听说有用FFMpeg去除水印的方式, 待会问问ChatGPT或者bing吧. (我现在用百度越来越少了啊...... 除了百度网盘); 好像是专门用来去视频文件的水印的, 不适用图片的水印去除.
学习资源:
Python如何批量去除图片上的LOGO(针对LOGO色素不复杂情况)_peng_wei_kang的博客-CSDN博客_python图像去除人工标记
Python批量图片去水印,提高工作效率 - chingho - 博客园 (cnblogs.com)
预研究之后, 我觉得目前我成本最低的方式 (肯定不是最好, 最好的方式还是全部使用深度学习的解决方法) : 💩
思路一: 深度学习的方式
1- 人工: 根据水印情况, 做一些特征的水印模板图片(mask)
2- 程序自动判断图片(四个角落上)是否有水印 🐸
3- 程序根据图片的尺寸和水印所在的位置, 使用mask去除水印
我可以将水印的情况做成相同的模板, 但是问题来了, 如何程序如何自动识别出水印所在的位置呢?? 还是要用的深度学习的方法
Github上有一个开源项目: rohitrango/automatic-watermark-detection: Project for Digital Image Processing (github.com)
折腾了半天, 阅读源码发现这玩意需要 一定的环境啊
ChatGPT说:
如果你的 Python 是 32 位版本的,那么 TensorFlow 不会直接支持。TensorFlow 官方只支持 64 位版本的 Python。不过,你可以考虑使用一些非官方的 TensorFlow 发行版,比如 TensorFlow for 32-bit Windows,该版本可以在 32 位版本的 Python 上运行。你可以访问该发行版的官方网站(https://github.com/fo40225/tensorflow-windows-wheel)来获取更多信息和安装说明。但需要注意的是,非官方的 TensorFlow 发行版可能会存在稳定性和兼容性方面的问题。如果你需要使用 TensorFlow 进行重要的项目开发,建议使用官方支持的 64 位版本的 Python。
思路二: 借助OpenCV工具+数学方法去除
图片文件(jpg/jpeg/png)的特征:
1- 图片要么横版/要么竖版 (宽>高 就是横版; 宽<高 就是竖版);
2- 我们假设所有的logo水印都在图片的上眉和下眉的左中右三个位置的其中一个
图片中的logo都是 文字形状, 如@今日头条之类的
[人工]可以事先用PS工具 提取出这些logo上的颜色值🔴 ; 并写好到json文件中; 例如:
# logo类型的颜色值
{
"logo1":{
"logotitle": "今日头条"
"temp_file": "logo_temp1.jpg",
"logo_location": {
"left_top": "true" # 上眉有left_top / top_center/ right_top; 下眉有right_bott / bott_center / right_bott
"box": "left_top_x, left_top_y, right_bott_x, right_bott_y" # 这是左上角和右下角的位置
},
"rgb_color_1": "200,200,200",
"rgb_color_2": "...",
"rgc_color_3": "..."
},
"logo2":{
.....
}
}
3- 所有图片中的logo水印一般不多,不会超过20种
4- [人工] 有logo水印的图片我们全部集中放在一个目录下面, 这个目录下面再按不同的logo类型再划分目录
(目前还做不到,将所有不同logo类型的图片放在一个目录下面批量处理, 后面想了一个特殊的方法)
5- 单张图片的logo去除方法:
用Python + OpenCV三步去除水印,去水印需要使用的库:cv2、numpy。cv2是基于OpenCV的图像处理库,可以对图像进行腐蚀,膨胀等操作;numpy这是一个强大的处理矩阵和维度运算的库
图片去水印原理 1、标定噪声的特征,使用cv2.inRange二值化标识噪声对图片进行二值化处理,具体代码:cv2.inRange(img, np.array([200, 200, 240]), np.array([255, 255, 255])),把[200, 200, 200]~[255, 255, 255]以外的颜色处理为0; 2、使用OpenCV的dilate方法,扩展特征的区域,优化图片处理效果; 3、使用inpaint方法,把噪声的mask作为参数,推理并修复图片。
去掉图片右下角的水印步骤 1、从源图片,截取右下角部分,另存为新图片; 2、识别水印,颜色值为:从json文件中获得 3、去掉水印,还原图片; 4、把源图片、去掉水印的新图片,进行重叠合并;
如何识别不同的logo类型呢(这样就不需要人工对图片分类,分目录了, 也就是取代上面的第四步人工操作了)
思路: 采用OCR文字识别后再比对 (哈哈哈, 我真实一个小机灵 🐶 )
1- 裁减图片的上眉 和 下眉图片 ; 上眉和下眉高度都不会超过100;
2- 对上眉和下眉图片采用 用ocr识别文字
3- 用文字找到对应的 logo 类型,
采用百度飞浆的OCR包
安装:
可以先阅读: 避坑教程:最新百度PaddleOCR文字识别成功下载安装保姆级手把手教程 - 知乎 (zhihu.com)
# 先安装wheel (可以在系统上全局安装,也可以在虚拟环境上安装)
pipenv install wheel
# 建议使用whl下载安装 shapely
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
pipenv install paddleocr -i
# For windows users: If you getting this error OSError: [WinError 126] The specified module could not be found when you install shapely on windows. Please try to download Shapely whl file here.
模型选择:
PaddleOCR/README_ch.md at release/2.6 · PaddlePaddle/PaddleOCR (github.com)
使用:
可以看看代码示例, 官方文档paddleocr · PyPI
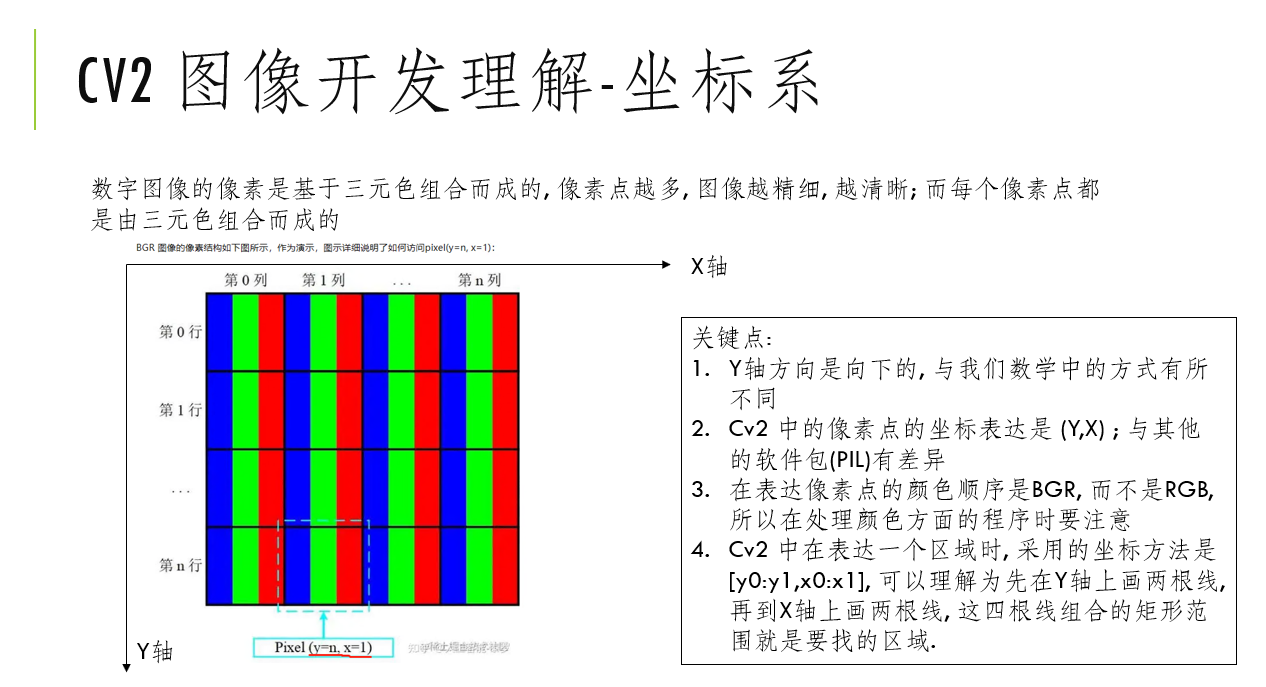
学习: 弄懂图像的坐标系 / 宽高的基本属性

请仔细阅读: 究极清晰!一文带你看懂OpenCV中的坐标系与图像通道顺序 - 知乎 (zhihu.com)
关于CV2 图像开发的理解
通过实验终于可以理解cv2 图像二值化的意思了, 二值化实际上是将图片转换为 黑白两种色彩. 转换的条件就是通过颜色值的上限 / 下限来处理.
而颜色的上限/ 下限的意思就是, BGR 三个数值的合值;

日常运行过程: (For Windows)
( 🐛 运营人员使用, 暂未考虑工具产品化; 需要使用人员对python开发有一定的了解, 至少安装环境是必须掌握的 )
🙏个人PC(或者服务器)上 请事先 安装好Python3 及相关的包环境(numpy / cv2 / PIL); 强烈建议是在Python的虚拟环境中安装
- 1- 将python项目目录复制到指定位置, 并对这个位置建立虚拟环境 ( 在CMD终端窗口中执行
pipenv install), - (待补充 目录结构)
- 2- 线下手工用PS工具 提取出这些logo上的颜色值🔴 ; 并写好到json文件(static/logo_temp.json)中, JSON文件的格式参考上面
- 3- 将要处理的图片复制到 待处理的目录( static/images/img_src / <当天> ) 中;
- 4- 执行命令行程序
python rm_wm.py清除logo水印 - 5- 检查清除logo效果, 请打开清除后的文件目录 (static/images/img_new/ <当天>) 检查新生成的图片
上面是第一次使用过程, 后续每次增加一种新的logo去图片时, 请先维护JSON文件
如果后不需要增加新的logo时, 其实只需要执行两步就可以了; 1- 复制源图片; 2- 执行命令
小结
1- 根据上面的思路二进行实现
2- 整个过程中人工只需要将图片中的logo类型在JSON文件 先标识好就可以了 (后续可以使用JQuery在前端页面上实现截图,定位,取色值, 并记录到JSON中)
好累:休息休息!!!

四. 开发实现
4.1. 环境安装
开发环境:
第一次进行开发时, 需要开发人员自行安装, 我的开发环境 Windows 10 + VSCODE
建立虚拟环境:
# 1-创建虚拟环境
pipenv install
# 2-设置全局Python 路径
# 请在pipenv的虚拟环境目录(Scripts)中的 activer.bat 文件末尾加上一句, 把你的python全局包目录加上去, C:\Python38\Lib\site-packages是我的python包路径
@set PYTHONPATH=%PYTHONPATH%;C:\Python38\Lib\site-packages
# 3-设置 pipenv 的 国内镜像, 修改pipfile
[[source]]
url = "https://pypi.tuna.tsinghua.edu.cn/simple"
verify_ssl = true
name = "pip_conf_index_global"
# 4-升级一下虚拟环境中的pip 版本, 一定注意要与系统中pip版本保持一致
pipenv run python -m pip install --upgrade pip
安装第三方软件包
# 5-开发运行时, 第三方包安装
pipenv install moment pillow wheel
pipenv install numpy
pipenv install opencv-python
安装百度飞浆OCR
# 6- 建议使用whl下载安装 shapely
# whl 包已经 下载放置在项目 install-package 目录中(我的环境是python 3.8 32bit) :
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
pipenv install shapely
# 7- 这个是在虚拟环境中安装
pipenv install paddlepaddle
pipenv install paddleocr
# 这是在全局系统中安装, 如果是全局系统中安装的飞浆, 并且想在虚拟环境中使用, 请在pipenv的虚拟环境目录(Scripts)中的 activer.bat 文件末尾加上一句, 把你的python包目录加上去
@set PYTHONPATH=%PYTHONPATH%;C:\Python38\Lib\site-packages
python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
# For windows users: If you getting this error OSError: [WinError 126] The specified module could not be found when you install shapely on windows. Please try to download Shapely whl file here.
如果是在VSCODE中开发, 请在设置中加上你的本地系统的包路径
要让 VS Code 找到你设置的虚拟环境中的包和系统已安装的包,你需要在 VS Code 中进行一些配置。
- 首先,打开 VS Code 并进入你的 Python 项目。
- 然后,按下 "Ctrl+Shift+P" (Windows) 或 "Cmd+Shift+P" (Mac) 打开命令面板,输入 "Python: Select Interpreter" 并选择你设置的虚拟环境。
- 接下来,你需要在 VS Code 中配置你的 Python 路径。点击左下角的齿轮图标打开设置,然后搜索 "python.pythonPath"。将其设置为你想要使用的 Python 解释器路径,这个路径应该是你虚拟环境中的 Python 解释器路径。
- 如果你想让 VS Code 找到你系统已经安装的包,你可以在 VS Code 中添加 Python 解释器路径和系统安装的包路径。在设置中搜索 "python.autoComplete.extraPaths" 并添加你想要添加的路径。例如,如果你的系统安装的包路径为 "/usr/local/lib/python3.9/site-packages",你可以将 "python.autoComplete.extraPaths" 设置为 ["/usr/local/lib/python3.9/site-packages"]。
- 最后,你需要重新启动 VS Code 以使配置生效。现在,你应该可以在 VS Code 中找到你设置的虚拟环境中的包和系统已安装的包了。
好吧, 开始享受代码吧
运行环境
如果是在运营时只需在项目目录下面运行一行命令即可, 如果提示百度飞浆OCR安装失败则需要参考上面的过程, 手工单独安装飞浆的OCR
pipenv install
4.2. 程序结构说明
# windows 生成目录树的命令
tree . /f > tree.txt
RM_WM
│ Pipfile
│ Pipfile.lock
│ Readme.md
│ rm_wm.py # 程序入口
│
├─common # 内部程序
│ logo_ocr.py # ocr识别 logo
│ main.py # 组织程序
│ wm_action.py # 水印处理程序
│ wm_check.py # 水印检查程序
│ __init__.py
│
├─conf
│ config.py # 程序参数配置
│ __init__.py
│
├─install-package
│ Shapely-1.8.2-cp38-cp38-win32.whl
│
├─static
│ └─images
│ ├─img_new # 按日期存放去除logo水印的目录
│ ├─img_src # 原始图片目录
│ ├─img_temp # 处理过程中的临时目录
│ └─logo_json # logo样本目录
│ logo_temp.json
│
└─templates # 暂时无用
4.2.1 测试代码
测试paddleocr
4.2.2 辅助功能
用 Python + CV2 实现下面功能: 图片颜色拾取和图片区域坐标显示
期望操作步骤:
1- 在CV2 窗口中打开一个图片,
窗口分成左右两部分, 左边是图片区域, 右边是信息显示区域(占20%),
信息显示区域中的文字是可以复制的
2- 鼠标在图片上点击, 信息显示区域上显示点击的像素的坐标, 颜色(BGR 和 HSV)
3- 鼠标按住-->移动-->松开操作, 信息显示区域上显示这次操作的鼠标按住时的坐标和松开时的坐标
请帮忙用 Python + CV2 实现, 如果还另外需要其他第三方库, 你也可以自行选择.
附录,
我想做一个页面功能, 我在前端页面上放一个Canvas, 在Canvas上进行操作, 然后,希望将这个Canvas图像传递到服务器端保存为一张图片, 使用的相关技术:
前端: Bootstrap5 + Canvas + FormData + Jquery3.6 + Ajax
后端: Flask 2.2
前端代码样例
<canvas id="cvs002"></canvas>
<button type="button" class="btn btn-outline-secondary mt-2 mb-3 ml-5" onclick="javascript:uploadFile();">保存蒙版</button>
请你帮忙补充前后端相关代码.

作者: CLP ; 日期: 2023-2-26 ; 地点: 临沂; 天气: 晴
QQ: 53258372; Mail : 53258372@QQ.com
微信:
